Project 5
Project 5Part A0. Setup1.1 Implementing the Forward Process1.2 Classical Denoising1.3 One-Step Denoising1.4 Iterative Denoising1.5 Diffusion Model Sampling1.6 Classifier Free Guidance1.7 Image-to-image Translation1.7.1 Editing Hand-Drawn and Web Images1.7.2 Inpainting1.7.3 Text-Conditional Image-to-image Translation1.8 Visual Anagrams1.9 Hybrid ImagesPart B1.1 Implementing the UNet1.2 Using the UNet to Train a Denoiser1.2.1 Training1.2.2 Out-of-Distribution Testing2.1 Adding Time Conditioning to UNet2.2 Training the UNet2.3 Sampling from the UNet2.4 Adding Class-Conditioning to UNet2.5 Sampling from the Class-Conditioned UNet
Part A
0. Setup
I set the random seed as 11220099 to generate images from the DeeoFloyd IF diffusion model. Below are examples of generated images with num_inference_steps=5 and num_inference_steps=15.
Step=5:
 |  |  |
|---|---|---|
| an oil painting of a snowy mountain village (stage 1) | a man wearing a hat (stage 1) | a rocket ship (stage 1) |
 |  |  |
| an oil painting of a snowy mountain village (stage 2) | a man wearing a hat (stage 2) | a rocket ship (stage 2) |
Step=15:
 |  |  |
|---|---|---|
| an oil painting of a snowy mountain village (stage 1) | a man wearing a hat (stage 1) | a rocket ship (stage 1) |
 |  |  |
| an oil painting of a snowy mountain village (stage 2) | a man wearing a hat (stage 2) | a rocket ship (stage 2) |
We can see that the images generated with more inference steps have significantly higher quality.
1.1 Implementing the Forward Process
To efficiently create a noised image in different time steps, I followed the formula below to do the forward process.
, where
Below are examples of different noise levels.
 |  |  |  |
|---|---|---|---|
| clean |
1.2 Classical Denoising
The classical denoising approach which uses Gaussian blur filtering can hardly give good results. Below are examples.
 |  |  |
|---|---|---|
1.3 One-Step Denoising
The pre-trained U-net which is trained to estimate the noise added in an image can denoise much better. Given the noised image at the time step
, where
| Clean | ||||
|---|---|---|---|---|
| Image in various noise level | | | | |
| One-step denoise result | N/A |  |  |  |
1.4 Iterative Denoising
We can also use iterative denoising to get better results. I followed the provided formula to compute the estimated image in the previous time step.
, where
 |  |  |  |  |  |
|---|
Compared with other approaches:
|  | |  |  |
|---|---|---|---|---|
| Original | Noised | Iterative denoised | One-step denoised | Gaussian filter |
1.5 Diffusion Model Sampling
Using pure noises, I sampled random images from the diffusion model with the prompt "a high quality photo."
 |  |  |  |  |
|---|
1.6 Classifier Free Guidance
The Classifier-Free Guidance is to estimate two noises in every iteration. One of them
, where
I used "a high quality photo" as a conditional prompt and "" as an unconditional prompt. Below are the results.
 |  |  |  |  |
|---|
This gives us much better images compared to the images from the last section.
1.7 Image-to-image Translation
I leveraged the CFG to edit the existing images. I first noised the original image in different levels, and iteratively denoised them with CFG. Below are examples.
| Noise level | 1 | 3 | 5 | 7 | 10 | 20 | Original |
|---|---|---|---|---|---|---|---|
| Campanile |  |  |  |  |  |  | |
| Professor |  |  |  |  |  |  |  |
| UC Berkeley |  |  |  |  |  |  |  |
1.7.1 Editing Hand-Drawn and Web Images
I used this procedure on non-realistic images (web images and hand-drawn images).
| Noise level | 1 | 3 | 5 | 7 | 10 | 20 | Original |
|---|---|---|---|---|---|---|---|
| Frieren |  |  |  |  |  |  |  |


1.7.2 Inpainting
By using mask, we can keeps some area in the images unchanged during the denoising process. Formally, the image
, where



1.7.3 Text-Conditional Image-to-image Translation
I used "a rocket ship" as a conditional prompt to translate my images into rocket ships. The process was done by using iterative CFG mentioned in section 1.6. The only thing different was the conditional prompt.

1.8 Visual Anagrams
To generate images look like one thing in a side and look like another thing when flipped upside down, we can denoise with the average of two noises. One of them is the "normal noise" and the other one is the "flipped noise".
, where
 |  |
|---|---|
| an oil painting of people around a campfire | an oil painting of an old man |
 |  |
| a pencil | a rocket ship |
 |  |
| a lithograph of waterfalls | a lithograph of a skull |
1.9 Hybrid Images
Similarly, processing on two estimated noises and averaging them allows us to play different tricks. Therefore, performing low-pass and high-pass filtering on the noises can give us hybrid images.
 |  |  |
|---|---|---|
| skull(far) + waterfall(close) | a man wearing a hat + a rocket ship | a photo of a man + a photo of the amalfi coast |
For the low-pass filtering, I used kernel size = 33 and sigma = 2.
Part B
1.1 Implementing the UNet
I followed the figures and instructions on the project description to implement the UNet. The architecture of the UNet is defined as follow:
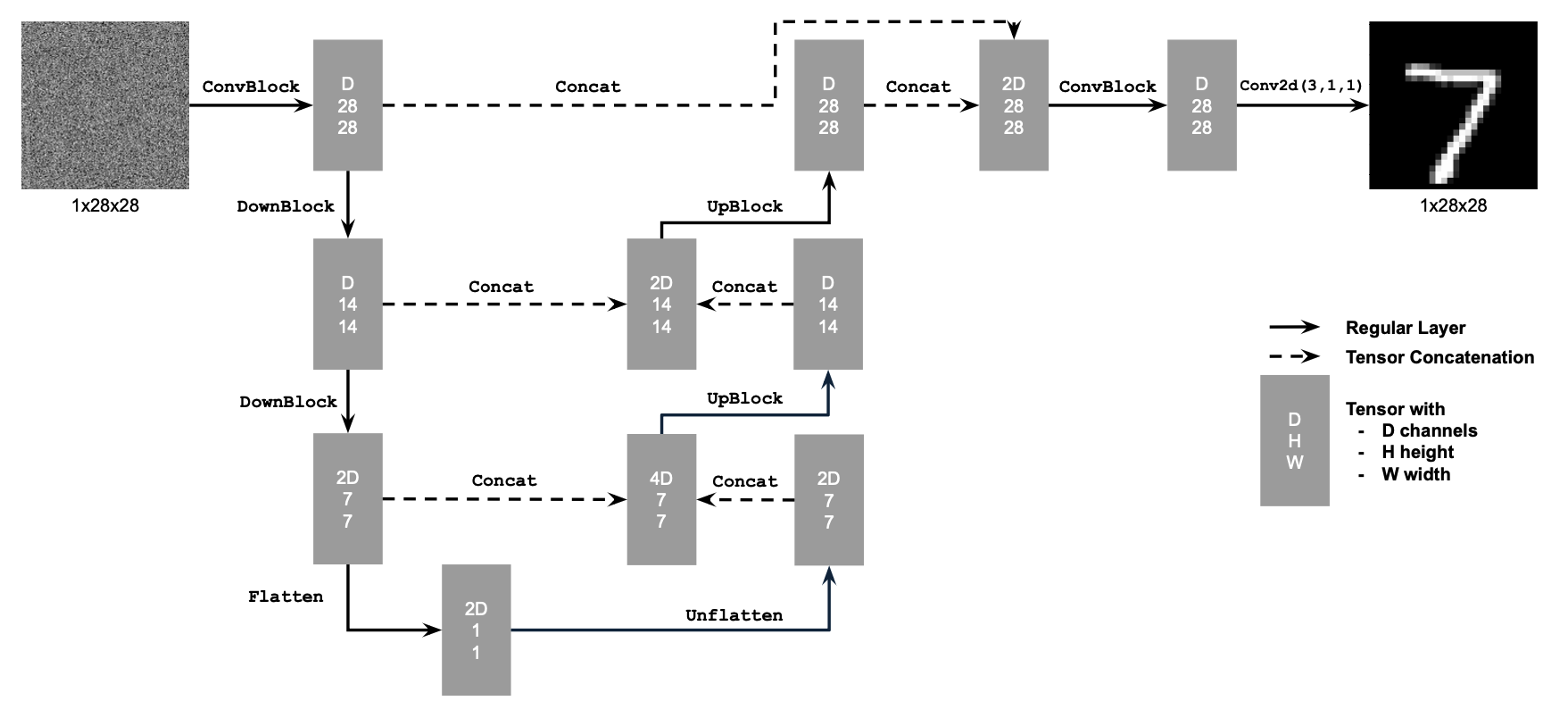
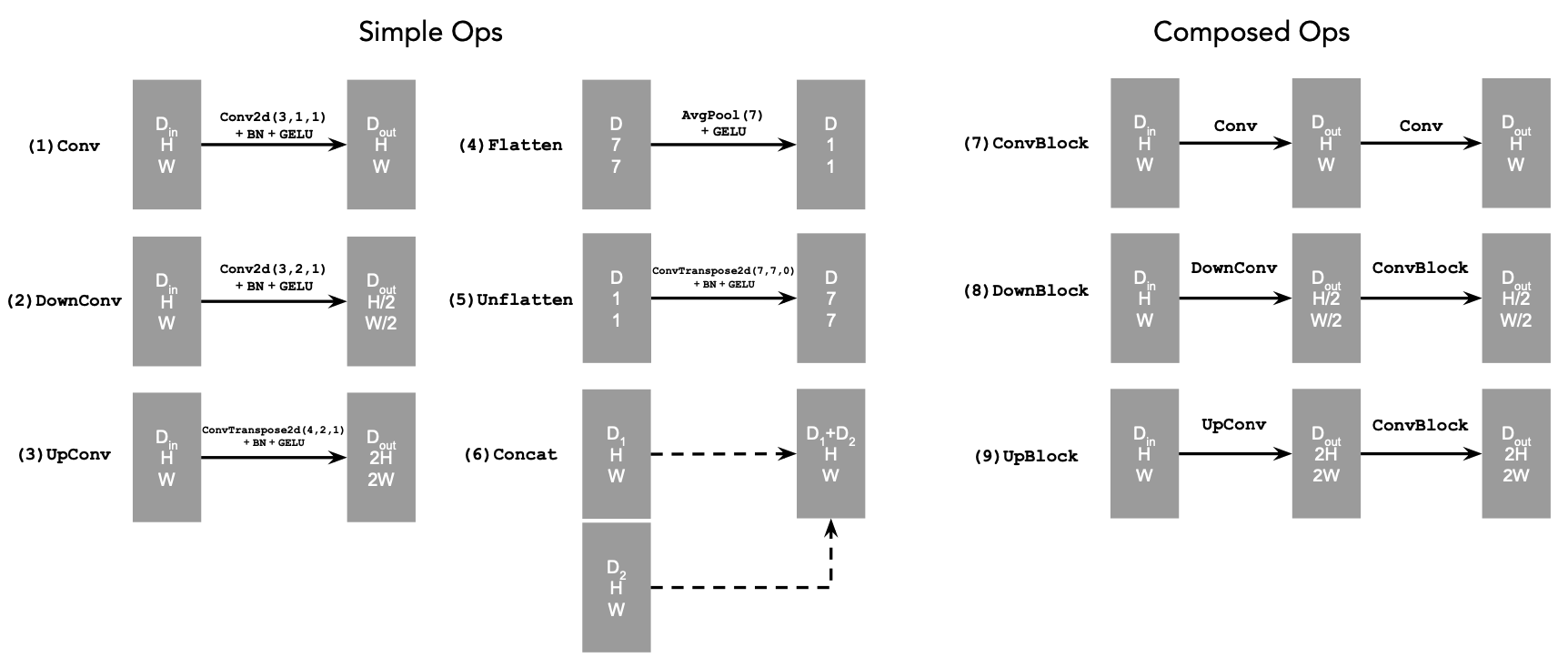
1.2 Using the UNet to Train a Denoiser
To train an UNet as a denoiser, I used the gaussian noise to add noise to images. Below are some examples that add Gaussian noise to MNIST dataset.

1.2.1 Training
I trained an one-step denoiser to denoise noisy images. The noisy images were obtained by adding gaussian noise with
Hyper-parameters:
xxxxxxxxxx41Epoch: 52Batch size: 2563Optimizer: Adam4Learning Rate: 1e-4
I logged the loss every 10 steps to plot the loss curve.
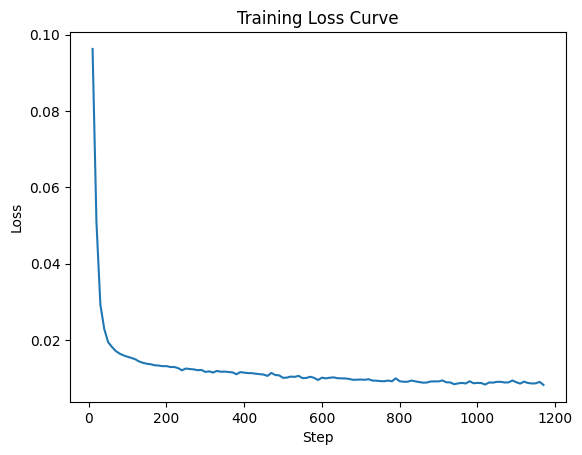 |
|---|
| Loss curve |
 |
| Results after training 1 epoch |
 |
| Results after training 5 epochs |
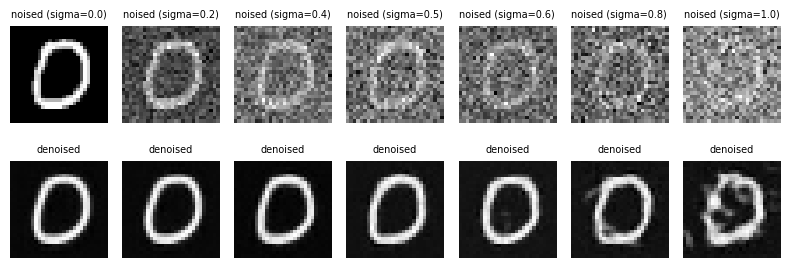
1.2.2 Out-of-Distribution Testing
Since my denoiser is trained on MNIST digits noised with
2.1 Adding Time Conditioning to UNet
To train a diffusion model that estimate the noise at every time step, I started with adding time conditioning to UNet (as project description suggested). This is done by adding two fully-connected layers to the UNet.
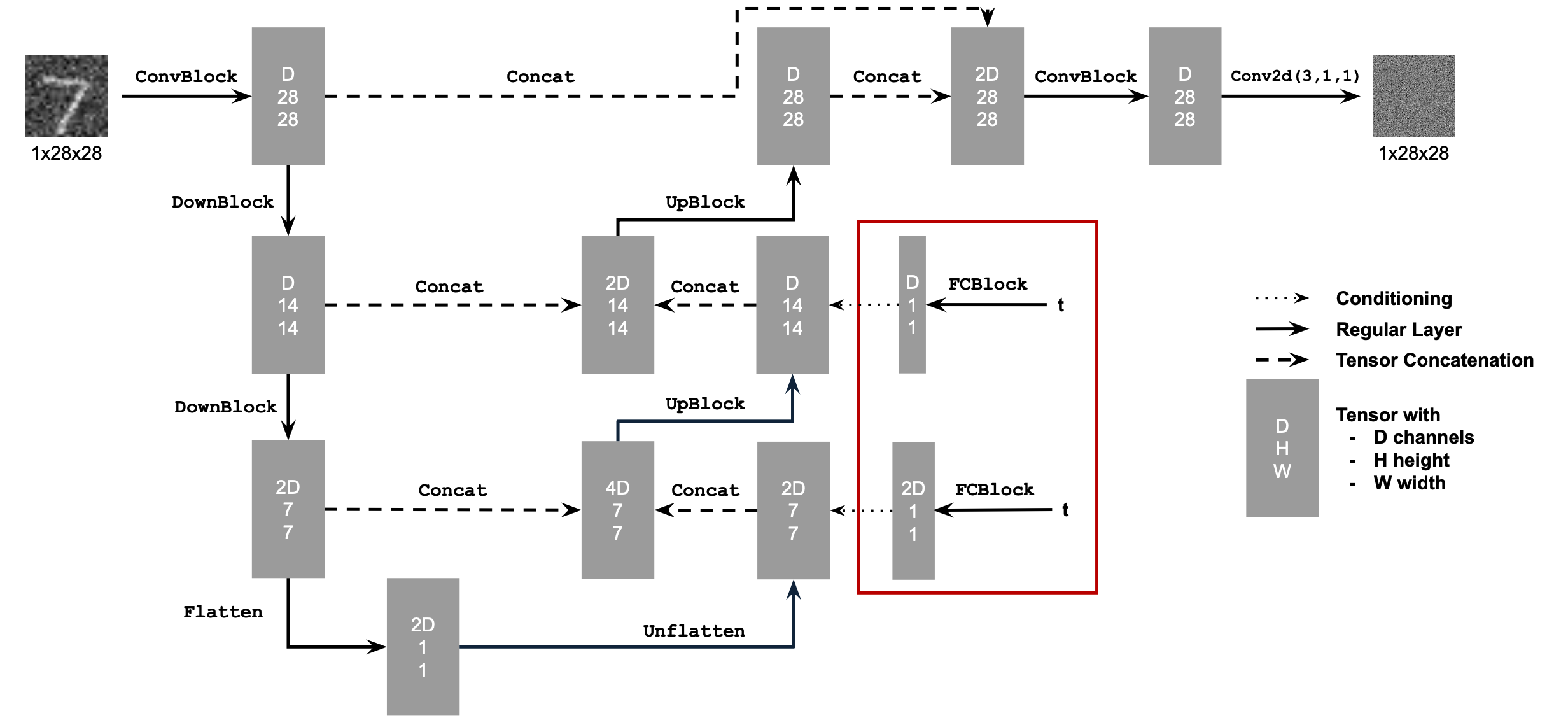
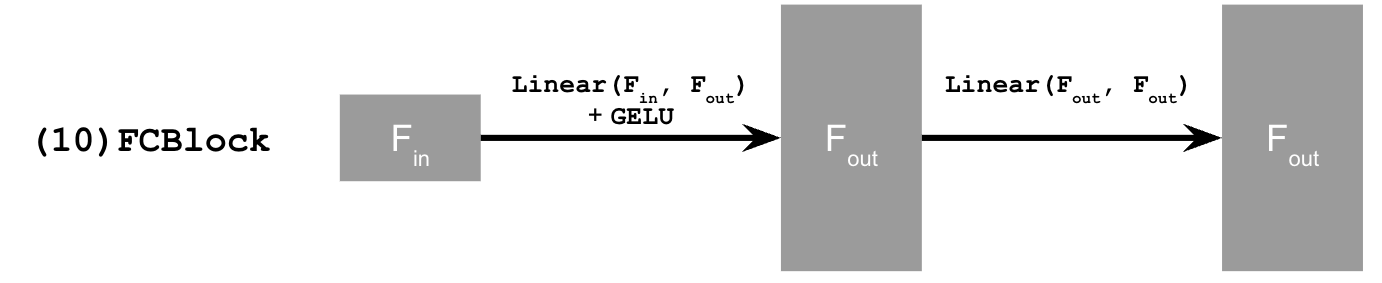
2.2 Training the UNet
I used the hyper-parameters below:
xxxxxxxxxx41Epoch: 202Batch size: 1283Optimizer: Adam with exponential decay scheduling (gamma = 0.1^(1/20))4Learning Rate: Start at 1e-3
I logged the loss every 10 steps to plot the loss curve.
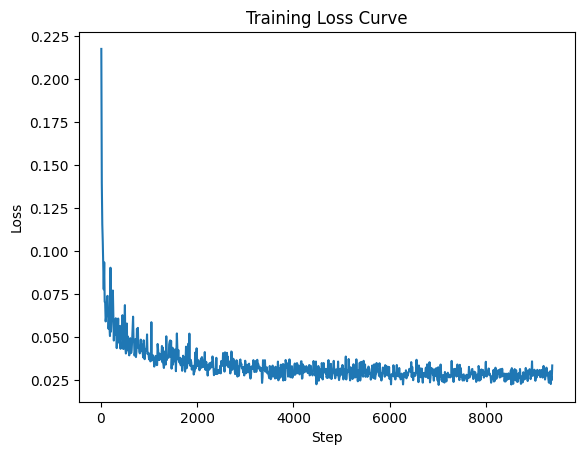
2.3 Sampling from the UNet
The time-conditional sampling is similar to section 1.4 in Part A.
I used this equation to iteratively denoise. Below are examples.
 |
|---|
| Results after training 5 epochs |
 |
| Results after training 20 epochs |
2.4 Adding Class-Conditioning to UNet
Class-conditioning is added to UNet by adding two fully-connected layers. During the training process, I passed class labels into the model. That is,
Training hyper-parameters:
xxxxxxxxxx41Epoch: 202Batch size: 1283Optimizer: Adam with exponential decay scheduling (gamma = 0.1^(1/20))4Learning rate: start at 1e-3
I logged the loss every 10 steps to plot the loss curve.
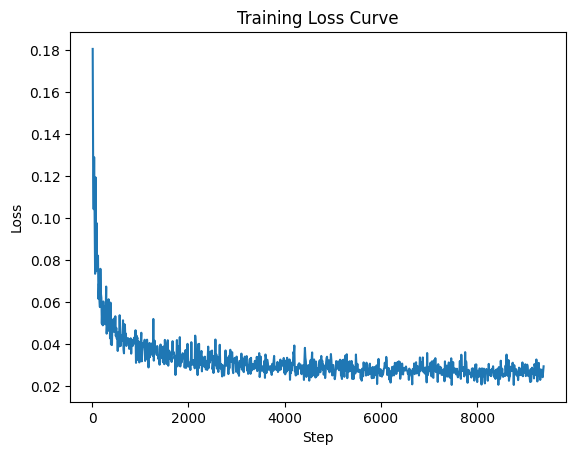
2.5 Sampling from the Class-Conditioned UNet
The sampling was very similar to section1.6 in Part A. Using CFG to guide the model do the class-conditioned estimates.
 |
|---|
| Results after training 1 epoch |
 |
| Results after training 5 epochs |
 |
| Results after training 20 epochs |